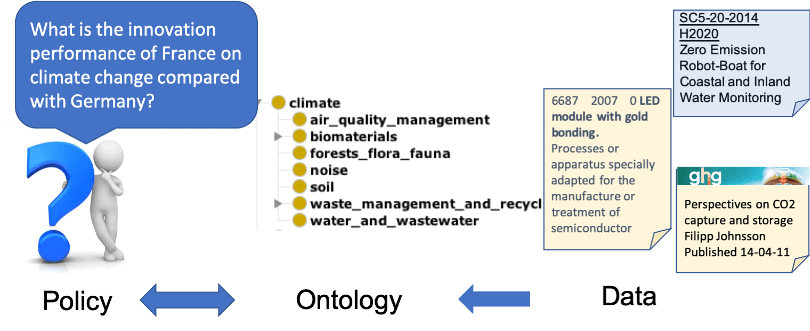
The RISIS-KNOWMAK approach employs ontologies as a bridge between the users and the underlying data: on the one hand, they enable users to browse topics, access related topics, and widen their search. On the other hand, the ontology enables to connect the data sources to relevant topics by means of annotation (tagging).
Ontology structure and topics
The ontology structure is built in three layers, the first one corresponding to KET and SGC. Unlike classifications, the ontology structure is hierarchical but nevertheless allows multiple inheritance (i.e. cross-linkages between branches).
For example, “nanobiotechnology” is a subclass of both “nanoscience and technology” and “biotechnologies”.
Multiple inheritance is required because terms and concepts are not unique to single KETs and SGCs – there is much overlap in technology between these areas, which needs to be reflected in the system.
Vocabularies
- Topics within the ontology are associated with vocabularies, i.e. sets of words, which are associated with one or more topics. For example, “tumour imaging” might be an instance of the class “nanotechnology in cancer”.
Vocabularies have two functions:
♦ to link topics with data items, for example publications. Data items are annotated with keywords and, through them, can therefore be associated to topics;
♦ to link topics with search queries by users.
Vocabularies are constructed from different types of texts, including policy documents, publication abstracts, patent descriptions, and summaries of research projects to reflect the different languages used in these documents.
Access to the ontology by users
The ontology is also available as an entry point to the tool for users. Users can select the topics of interest within the ontology and then access to the relevant indicators by class.
